Das batch-mean-Verfahren ist eine Methode zur Gewinnung von Konfidenzintervallen ("Vertrauensgrenzen") für stationäre Prozeßparameter auf der Grundlage einer einzigen Prozeßtrajektorie.
Dem batch-mean-Verfahren liegt die Idee zugrunde, den anscheinend unnötigen Aufwand mehrerer unabhängiger Simulationsläufe (wobei jedesmal auch die transiente Anfangsphase mit simuliert werden muß!) zu vermeiden, indem versucht wird, aus einem sehr langen Simulationslauf mehrere stochastisch unabhängige Schätzwerte zu gewinnen.
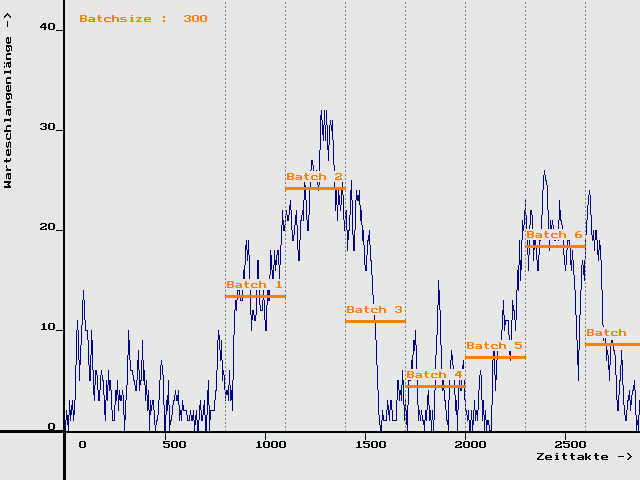
Zu diesem Zweck wird der "stationäre Teil" der Zeitachse in disjunkte Abschnitte der Länge deltaT - die sogenannten Batches - unterteilt. Die Vorgehensweise ist im folgenden Bild anhand der Warteschlangenentwicklung x(t) beim Skilift-Problem demonstriert ( dabei wurde das Ende der transienten Anfangsphase bei T* = 800 ZE angenommen und deltaT = 300 ZE gewählt):
Jedem Batch wird ein eigener Schätzwert b[k] zugeordnet. Soll - wie im betrachteten Beispiel - der stationäre Mittelwert ” = Ex() des Prozesses x(t) bestimmt werden, so lautet die Schätzfunktion für den Mittelwert des Zeitabschnittes j (der batch mean b[j] )
Obwohl die Batchmittelwerte b[k] allesamt erwartungstreue Schätzungen für den stationären Mittelwert ” sind, bildet die Folge {b[k]} keine Stichprobe im Sinne der mathematischen Statistik, da die den Werten zugrundeliegenden Zufallsgrößen nicht unabhängig sind!
Dieser Effekt wird besonders deutlich sichtbar, wenn das Zeitintervall deltaT verkleinert wird ( hier eine andere Trajektorie mit deltaT = 100 ZE):
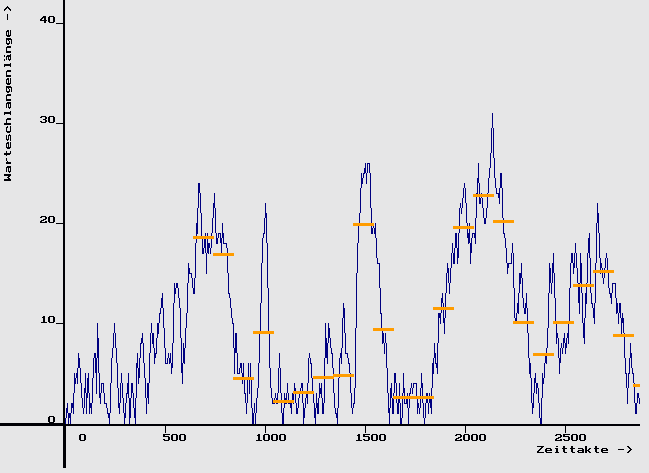
Die Erklärung ist einfach: Warteschlangenmodelle sind "träge"; wenn nur 1 Bedienkanal vorhanden ist, dauert der Abbau einer zufällig entstandenen Warteschlange immer eine gewisse Zeit. Folglich ist es sehr wahrscheinlich, daß auf einen extrem großen Wert b[k] erneut ein überdurchschnittlich großer batchmean b[k+1] folgt.
Wie stark benachbarte Batchmittelwerte voneinander abhängen, kann über die Festlegung von deltaT (auch - vor allem bei zeitdiskreten Prozessen - als Batch-Size B bezeichnet) beeinflußt werden: Je größer der Batch-Size gewählt wird, um so geringer ist die Abhängigkeit benachbarter Werte! Für jeden Prozeß kann somit ein "hinreichender BatchSize" B* gefunden werden, bei dem die Abhängigkeiten vernachlässigbar klein werden und die Folge {b[k]} somit wie eine Stichprobe behandelt werden kann:
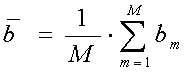 . . . Gesamtmittel (Punktschätzung für ” )
. . . Gesamtmittel (Punktschätzung für ” )
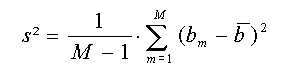 . . . Stichprobenvarianz sČ
. . . Stichprobenvarianz sČ
Bei hinreichend großem Batch-Size kann die Konstruktion eines Konfidenzintervalles für ” in der gleichen Weise wie bei den Einzelschätzwerten ”*[i] aus unabhängigen runs erfolgen. Dabei muß berücksichtigt werden, daß die Population der Batchmittelwerte b[i] - ebenso wie die der ”*[i] im Falle unabhängiger runs - i. allg. nicht normalverteilt ist!
Leider ist es nicht möglich, einen Pauschal- oder Richtwert für B* anzugeben. Ausschlaggebend für die Wahl von deltaT bzw. B* ist die Autokorrelationsfunktion
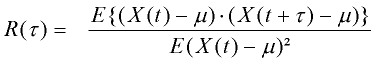
des stationären Prozesses x(t): Je schneller die Funktion R(tau) mit wachsendem tau gegen 0 strebt (mit anderen Worten: je weniger der Prozeß selbstkorreliert ist), um so kleiner kann der Batchsize B festgelegt werden.